What is Fantasy Basketball ?¶
Fantasy sport
A fantasy sport (also known less commonly as rotisserie or roto) is a type of online game where participants assemble imaginary or virtual teams of real players of a professional sport. These teams compete based on the statistical performance of those players' players in actual games. This performance is converted into points that are compiled and totaled according to a roster selected by each fantasy team's manager. These point systems can be simple enough to be manually calculated by a "league commissioner" who coordinates and manages the overall league, or points can be compiled and calculated using computers tracking actual results of the professional sport. In fantasy sports, team owners draft, trade and cut (drop) players, analogously to real sports.
Basic Rules¶
Team owner drafts a team of 13 players
Each week owners select 10 active players
Owners collect points based on their picks' performance
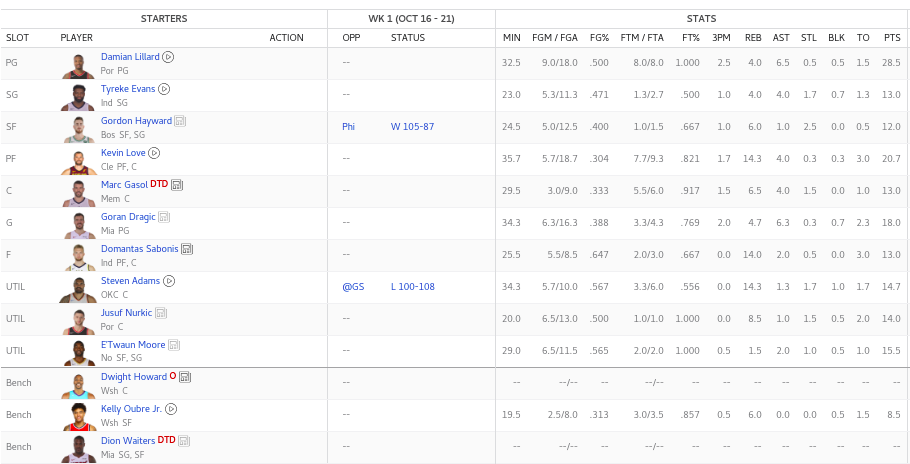
Each Player collects points from the following statistics¶
- Field Goals Made (FGM) 1.5
- Field Goals Attempted (FGA) -0.5
- Free Throws Made (FTM) 1
- Free Throws Attempted (FTA) -0.75
- Three Pointers Made (3PM) 1
- Three Pointers Attempted (3PA) -0.25
- Offensive Rebounds (OREB) 0.5
- Rebounds (REB) 1
- Assists (AST) 2
- Steals (STL) 2.5
- Blocks (BLK) 2.5
- Turnovers (TO) -1.75
- Points (PTS) 1
How to improve my team?¶
- Improve Draft Process
- Make smarter moves during the season (based on schedule and form)
Predict player's performance¶
- Use previous season's statistics to predict the next one
- Machine Learning
- Regression
- Neural Networks
Use Python¶
Pandas
Beautiful Soup
Jupyter
Seaborn / Plotly
Scikit Learn
Keras
Step 0.¶
Pandas¶
https://pandas.pydata.org/pandas-docs/stable/
pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
(venv) [nmichas@my-pc]$ pip install pandas
pandas.DataFrame¶
Two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns). Arithmetic operations align on both row and column labels. Can be thought of as a dict-like container for Series objects. The primary pandas data structure.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(6,4), columns=list('ABCD'))
df
Beautiful Soup¶
https://www.crummy.com/software/BeautifulSoup/
Install by:
(venv) [nmichas@my-pc]$ pip install beautifulsoup4
(venv) [nmichas@my-pc]$ pip install lxml
Parse and read all Players Statistics from Basketball-Reference website
https://www.basketball-reference.com/players/a/antetgi01.html
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = 'https://www.basketball-reference.com/players/a/antetgi01.html'
r = requests.get(url)
s = BeautifulSoup(r.text, 'lxml')
player_df = pd.read_html(r.text)[0]
player_df.head()
COLUMNS = ['Season', 'Age', 'Tm', 'Lg', 'Pos', 'G', 'GS',
'MP', 'FG', 'FGA', 'FG%', '3P', '3PA', '3P%',
'2P', '2PA', '2P%', 'eFG%', 'FT', 'FTA', 'FT%',
'ORB', 'DRB', 'TRB', 'AST', 'STL', 'BLK', 'TOV',
'PF', 'PTS']
player_df = player_df[COLUMNS]
player_df.head()
import re
player_df['Height'] = s.find(itemprop='height').get_text()
player_df['Weight'] = s.find(itemprop='weight').get_text()
regex = re.compile(
'(Guard|Forward|Point Guard|Center|Power Forward|Shooting Guard|Small Forward)')
player_df['Position'] = s.findAll(text=regex)[0].strip().split('\n')[0]
player_df.columns
Read All Player Names¶
(venv) [nmichas@my-pc]$ python get_all_players.py
players.csv should be a csv file of this form
name,shortname,href
Alaa Abdelnaby,abdelal01,/players/a/abdelal01.html
Zaid Abdul-Aziz,abdulza01,/players/a/abdulza01.html
Kareem Abdul-Jabbar,abdulka01,/players/a/abdulka01.html
Mahmoud Abdul-Rauf,abdulma02,/players/a/abdulma02.html
Tariq Abdul-Wahad,abdulta01,/players/a/abdulta01.html
Shareef Abdur-Rahim,abdursh01,/players/a/abdursh01.html
Tom Abernethy,abernto01,/players/a/abernto01.html
Forest Able,ablefo01,/players/a/ablefo01.htmlRead all Statistics for every player¶
(venv) [nmichas@my-pc]$ python get_all_seasons.py
seasons.csv should be a csv file of this form
csv
Player,ShortName,Height,Weight,Position,BirthPlace,SeasonURL,Season,Age,Tm,Lg,Pos,G,...
Alaa Abdelnaby,abdelal01,6-10,240lb,Power Forward,Egypt,/players/a/abdelal01/gamelog/1991/,1990-91,22.0,POR,NBA,PF,43,0,6.7,1.3,2.7,0.474,0.0,0.0,,1.3,...
Alaa Abdelnaby,abdelal01,6-10,240lb,Power Forward,Egypt,/players/a/abdelal01/gamelog/1992/,1991-92,23.0,POR,NBA,PF,71,1,13.2,2.5,5.1,0.493,0.0,0.0,,2.5,...
Alaa Abdelnaby,abdelal01,6-10,240lb,Power Forward,Egypt,/players/a/abdelal01/gamelog/1993/,1992-93,24.0,TOT,NBA,PF,75,52,17.5,3.3,6.3,0.518,0.0,0.0,0.0,...df = pd.read_csv('seasons.csv')
df.sample(1)
Remove stats from players that changed team mid-season
df[['Player', 'ShortName', 'Season', 'Lg', 'Tm']].head(5)
df.drop(
df[df.duplicated(['ShortName', 'Season'], keep='first')].index,
inplace=True)
Drop Rows for No-NBA leagues and total career statistics
df[['Player', 'ShortName', 'Season', 'Lg', 'Tm']][df.Lg != 'NBA'].head(5)
df.drop(df[df.Lg == 'ABA'].index, inplace=True)
df.drop(df[df.Lg == 'BAA'].index, inplace=True)
df.drop(df[df.Lg == 'TOT'].index, inplace=True)
df.drop(df[df.Season == 'Career'].index, inplace=True)
Remove data from players with missing information
df[['Player', 'ShortName', 'Season', 'Lg', 'Tm', '3P', 'GS']][df['3P'].isnull()].head(5)
# drop players before 3P use
df.dropna(subset=['3P', '3PA'], inplace=True)
# drop players without info for Games Started
df.dropna(subset=['GS'], inplace=True)
# drop players with no height-weight info
df.dropna(subset=['Height', 'Weight'], inplace=True)
Convert Heigh and Weight to numeric
df[['Height', 'Weight']].sample(5)
def height_to_cm(h):
ft, inch = h.split('-')
inch = int(inch) + int(ft) * 12
return round(inch * 2.54, 1)
def remove_lb(w):
return int(w.replace('lb', ''))
df['Height'] = df['Height'].map(height_to_cm)
df['Weight'] = df['Weight'].map(remove_lb)
Convert season to numeric
min_season = int(df['Season'].min().split('-')[0])
def get_season(row):
return int(row['Season'].split('-')[0]) - min_season
df['Season_Numeric'] = df.apply(get_season, axis=1)
df[['Season', 'Season_Numeric']].sample(5)
Convert position to an array of Boolean values
def get_position_matrix(position):
positions = [0, 0, 0, 0, 0]
if 'Point Guard' in position:
positions[0] = 1
if 'Shooting Guard' in position:
positions[1] = 1
if 'Small Forward' in position:
positions[2] = 1
if 'Power Forward' in position:
positions[3] = 1
if 'Center' in position:
positions[4] = 1
if 'Guard' in position and 'Point Guard' not in position and 'Shooting Guard' not in position:
positions[0] = 1
positions[1] = 1
if 'Forward' in position and 'Power Forward' not in position and 'Small Forward' not in position:
positions[2] = 1
positions[3] = 1
return positions
position_matrix = []
for i, season_row in df.iterrows():
position_matrix.append(get_position_matrix(season_row['Position']))
position_matrix = pd.np.array(position_matrix)
for i, position in enumerate(['PG', 'SG', 'SF', 'PF', 'C']):
df['plays_' + position] = position_matrix[:, i]
giannis_df = df[df['Player'] == 'Giannis Antetokounmpo']
giannis_df[['Player', 'Position', 'plays_PG', 'plays_SG', 'plays_SF', 'plays_PF', 'plays_C']].head(1)
Calculate score
def get_score(row):
return row['FG'] * 1.5 + row['FGA'] * (-0.5) + row['FT'] + \
row['FTA'] * (-0.75) + row['3P'] + row['3PA'] * (-0.25) + \
row['ORB'] * 0.5 + row['TRB'] + row['AST'] * 2 + \
row['STL'] * 2.5 + row['BLK'] * 2.5 + \
row['TOV'] * (-1.75) + row['PTS']
df['Score'] = df.apply(get_score, axis=1)
giannis_df = df[df['Player'] == 'Giannis Antetokounmpo']
giannis_df[['Player', 'Season', 'Score']].head(5)
Find next season score - the target column
df.sort_values(['ShortName', 'Season_Numeric'], inplace=True)
g = df.groupby(['ShortName'])
next_season_score = list()
for i, gr in g:
next_season_score += list(gr['Score'].shift(-1))
df['Next_Season_Score'] = next_season_score
df.dropna(subset=['Next_Season_Score'], inplace=True)
giannis_df = df[df['Player'] == 'Giannis Antetokounmpo']
giannis_df[['Player', 'Season', 'Season_Numeric', 'Score', 'Next_Season_Score']].head(5)
# drop unnecessary columns
df.drop(
['BirthPlace', 'Season', 'Position', 'Player',
'SeasonURL', 'Lg', 'ShortName', 'Pos', 'Tm', 'Score'],
axis=1, inplace=True)
df.fillna(0, inplace=True)
df.reset_index(inplace=True)
df.drop(['index'], axis=1, inplace=True)
df.sample(5)
We can now use the following function to get an entirely numeric dataframe.
from clear_seasons_data import get_clear_final_data
df = get_clear_final_data()
from clear_seasons_data import get_clear_final_data
df = get_clear_final_data()
df.describe()
df.groupby("Age").mean()[['FG', '3P%', 'FT%', '2P%', 'TRB', 'AST', 'BLK', 'TOV', 'PF', 'PTS']].head(10)
df.groupby("Season_Numeric").mean()[['3P%', 'FT%', '2P%', 'TRB', 'AST', 'BLK', 'TOV', 'PF', 'PTS']].head(10)
A picture says more than a thousand words¶
Seaborn¶
Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics.
(venv) [nmichas@my-pc]$ pip install seaborn
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
from clear_seasons_data import get_clear_seasons_data
sns_df = get_clear_seasons_data()
sns_df.sample(5)
sns.distplot(sns_df['STL'])

sns.jointplot(x='BLK', y='TRB', data=sns_df, kind='reg')

test_df = sns_df[['Pos', 'TRB','AST','STL']]
sns.pairplot(test_df, hue='Pos', diag_kind='hist', hue_order=['PG', 'SG', 'SF', 'PF', 'C'])

sns.barplot(x='plays_PG', y='AST', data=sns_df)

sns.boxplot(x='Pos', y='TRB', data=sns_df, order=['PG', 'SG', 'SF', 'PF', 'C'])

sns.heatmap(sns_df[['TRB','AST','STL','BLK','TOV', '2P%', '3P%', 'eFG%', 'PF', 'Score']].corr(), annot=True)

Plotly for Python and Cufflinks¶
Plotly's Python graphing library makes interactive, publication-quality graphs online.
(venv) [nmichas@my-pc]$ pip install plotly
(venv) [nmichas@my-pc]$ pip install cufflinks
import pandas as pd
import numpy as np
import cufflinks as cf
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
cf.go_offline()
%matplotlib inline
plotly_df = get_clear_seasons_data()
plotly_df.iplot(
kind='scatter', x='Age', y='Score', text='ShortName', mode='markers',
layout={'autosize':False, 'width':800, 'height':600, 'hovermode': 'closest'})
# plotly and cufflinks does not work well with jupyter's slides
Scikit-learn¶
Scikit-learn is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
(venv) [nmichas@my-pc]$ pip install scikit-learn
Regression analysis
In statistical modeling, regression analysis is a set of statistical processes for estimating the relationships among variables. It includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables (or 'predictors'). More specifically, regression analysis helps one understand how the typical value of the dependent variable (or 'criterion variable') changes when any one of the independent variables is varied, while the other independent variables are held fixed.
Predict with Linear Regression¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from clear_seasons_data import get_clear_final_data
def get_train_test_datasets(df):
max_season = df['Season_Numeric'].max()
df_train = df[df['Season_Numeric'] != max_season]
df_test = df[df['Season_Numeric'] == max_season]
X_train = df_train.drop(columns=['Next_Season_Score'])
y_train = df_train['Next_Season_Score']
X_test = df_test.drop(columns=['Next_Season_Score'])
y_test = df_test['Next_Season_Score']
return X_train, X_test, y_train, y_test
regr_df = get_clear_final_data()
X_train, X_test, y_train, y_test = get_train_test_datasets(regr_df)
X_train.head(5)
y_train.head(5)
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(X_train,y_train)
lm.intercept_
lm.coef_
coeff_df = pd.DataFrame(lm.coef_,X_train.columns,columns=['Coefficient'])
coeff_df.transpose()
predictions = lm.predict(X_test)
plt.scatter(y_test,predictions)

sns.distplot((y_test-predictions),bins=50)

from sklearn import metrics
print('Mean Absolute Error :', metrics.mean_absolute_error(y_test, predictions))
print('Mean Squared Error :', metrics.mean_squared_error(y_test, predictions))
print('Root Mean Squared Error :', np.sqrt(metrics.mean_squared_error(y_test, predictions)))
Compare Other Regression Methods¶
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from clear_seasons_data import get_clear_final_data
compare_df = get_clear_final_data()
X = df.drop(columns=['Next_Season_Score'])
y = df['Next_Season_Score']
X.head()
y.head()
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet
a = 0.9
methods = [
('linear regression', LinearRegression()),
('lasso', Lasso(fit_intercept=True, alpha=a)),
('ridge', Ridge(fit_intercept=True, alpha=a)),
('elastic-net', ElasticNet(fit_intercept=True, alpha=a))
]
for name,met in methods:
met.fit(X,y)
p = met.predict(X)
e = p-y
total_error = np.dot(e,e)
rmse_train = np.sqrt(total_error/len(p))
print('Method: %s' %name)
print('RMSE on training: %.4f' %rmse_train)
print("\n")
Neural Networks with Keras and Tensorflow¶
Keras¶
Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research.
Tensorflow¶
TensorFlow™ is an open source software library for high performance numerical computation. Originally developed by researchers and engineers from the Google Brain team within Google’s AI organization.
import numpy
import pandas
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from clear_seasons_data import get_clear_final_data, get_train_test_datasets
keras_df = get_clear_final_data()
X_train, X_test, y_train, y_test = get_train_test_datasets(keras_df)
# define base model
def baseline_model():
# create model
model = Sequential()
model.add(Dense(30, input_dim=34, kernel_initializer='normal', activation='relu'))
model.add(Dense(10, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal'))
# Compile model
model.compile(loss='mean_squared_error', optimizer='adam')
return model
estimator = KerasRegressor(build_fn=baseline_model, epochs=200, batch_size=256, verbose=2)
estimator.fit(X_train, y_train)
predictions = estimator.predict(X_test)
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(y_test,predictions)

from sklearn import metrics
import numpy as np
print('MAE:', metrics.mean_absolute_error(y_test, predictions))
print('MSE:', metrics.mean_squared_error(y_test, predictions))
print('RMSE:', np.sqrt(metrics.mean_squared_error(y_test, predictions)))
Step 5.¶
Use the predictions
from clear_seasons_data import get_clear_final_data, get_train_test_datasets
final_df = get_clear_final_data(with_labels=True)
X_train, X_test, y_train, y_test = get_train_test_datasets(final_df)
labels_train = X_train[['Player']]
labels_test = X_test[['Player']]
X_train.drop(columns=['Player'], inplace=True)
X_test.drop(columns=['Player'], inplace=True)
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(X_train, y_train)
predictions = lm.predict(X_test)
labels_test['Prediction'] = predictions
prediction_df_sorted = labels_test.sort_values(by='Prediction', ascending=False)
prediction_df_sorted[:10]
prediction_df_sorted[10:20]
last_season_df = pd.read_csv('current.csv')
from clear_seasons_data import get_score
last_season_df['Score'] = last_season_df.apply(get_score, axis=1)
last_season_df = last_season_df.sort_values(by='Score', ascending=False)[['Player', 'Score']]
last_season_df.head(10)